处理 mysql 带 emoji 错误
今天领导让处理一个生产环境的 bug. 报错信息:
SQLSTATE[HY000]: General error: 1267 Illegal mix of collations (utf8_general_ci,IMPLICIT) and (utf8mb4_general_ci,COERCIBLE) for operation 'like'
这是一个 YII1.1 的项目, 简单看了一下错误消息及 API 的用途, 大概判断应该是搜索关键词带了 emoji 表情. 一般就是换一下表或表字段的字符集即可, 亦或是关键词过滤掉 emoji 字符即可.
检查了生产环境的数据库, 字符集都是使用 UTF8, collation 都是使用 utf8_unicode_ci, 然而无论是在本地还是在生产环境想手动复现这个问题基本都是无法复现, 只能在项目里面复现, 考虑到手动复现时 PDO 是手动创建的, 所以一直在考虑可能是 YII 创建的 PDO 配置了某项 ATTR 导致.
折腾了两三个钟都没定位到, 最终发现是 db connection 的配置有问题, 由于没有应用环境配置及配置模板, 且关键配置文件没有放到代码版本控制中 (懒政, 不作为), 同事发给我的 db 配置中使用的 charset 为 utf8, 而生产环境使用的是 utf8mb4. 所以导致的问题的发生.
所以最终问题的原因就是创建了连接后, 执行了 set names utf8mb4, 再执行 select * from demo where something='%😂%' 会报上面这个错误.
那么 set names 到底做了什么呢 ?
首先查清 character set 跟 collation 的区别, 以及字符集和字符编码的区别, 摘抄一下 阿里云 RDS 数据库内核组的文章:
字符和字符集(Character and Character set)
在计算机领域,我们把诸如文字、标点符号、图形符号、数字等统称为字符,包括各国家文字、标点符号、图形符号、数字等。而由字符组成的集合则成为字符集,是一个系统支持的所有抽象字符的集合。字符集由于包含字符的多少与异同而形成了各种不同的字符集,字符集种类较多,每个字符集包含的字符个数不同。我们知道,所有字符在计算机中都是以二进制来存储的。那么一个字符究竟由多少个二进制位来表示呢?这就涉及到字符编码的概念了。常见字符集名称:ASCII字符集、GB2312字符集、GBK字符集、GB18030字符集、Unicode字符集等。
字符编码(Character Encoding)
字符编码也称字符码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组),以便文本在计算机中存储和通过通信网络传输。我们规定字符编码必须完成如下两件事:1)规定一个字符集中的字符由多少个字节表示;2)制定该字符集的字符编码表,即该字符集中每个字符对应的(二进制)值。
一个简单的理解就是, 字符编码就是一个字符集的实现, 例如 UTF-8 就是一种 Unicode 字符集的实现.
Unicode 的实现方式不同于编码方式。一个字符的 Unicode 编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。Unicode 的实现方式称为 Unicode转换格式(Unicode Transformation Format,简称为 UTF)。
字符序
一组在指定字符集中进行字符比较的规则,比如是否忽略大小写,是否按二进制比较字符等等。
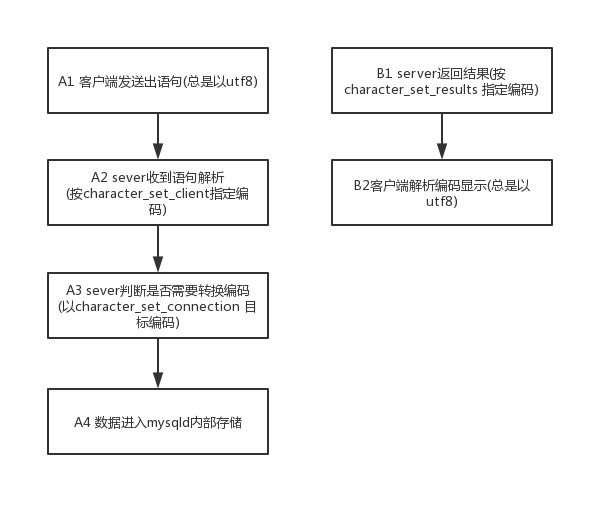
set names 做了什么?
在执行了 set names utf8mb4 之后, 会有 4 个 session 变量被改变值:
collation_connection=utf8mb4_general_ci
character_set_client=utf8mb4
character_set_connection=utf8mb4
character_set_results=utf8mb4
其中后面三个的定义用途为:
- character_set_client 是指客户端发送过来的语句的编码;
- character_set_connection 是指mysqld收到客户端的语句后,要转换到的编码;
- 而 character_set_results 是指server执行语句后,返回给客户端的数据的编码。
具体的理解可以查看: http://mysql.taobao.org/monthly/2015/05/07/
结合 mysql 的文档: https://dev.mysql.com/doc/refman/5.7/en/charset-repertoire.html
我的理解是, 之所以会出现 1267 错误, 是因为 mysql 在进行转换编码时, 有一些字符是无法从 a 字符集转换为 b 字符集的, 例如无法从将 emoji 从 utf8mb4 转换为 utf8, 所以才出现这样的错误. 当然这个理解可能还不够充分, 只能后续再慢慢整理了.
至于这个 bug 的解决方式, 就是把 emoji 表情去掉即可. 主要是业务场景允许这个操作.
参考
- 十分钟搞清字符集和字符编码
- MySQL之charset和collation
- wikipedia - UTF-8
- 字符编码
- set names 都做了什么
- 5分钟读懂MySQL字符集设置
- MySQL · 实现分析 · 对字符集和字符序支持的实现